
Second in a Series: Mastering Data Quality for Safe & Scalable AI
Saibal Banerjee, PhD and Steven Atneosen, JD
Introduction
In order to master data quality for safe and scalable AI, precision and recall go beyond the simplicity of accuracy by helping quantify the nature of classification errors. These metrics are essential for professionals aiming to safely scale AI systems that require precise data while maintaining regulatory compliance, especially in rarified data privacy environments like the EU’s GDPR.
When Precision Matters
Precision measures the correctness of positive predictions. Unlike overall accuracy, precision is a metric that can be defined on predicted class values. For example, in a spam filter, you want to minimize false positives – emails mistakenly marked as spam. High precision ensures that predicted spam is likely to be spam. As an example with a given test set, it answers the following question: How often is a particular value predicted by the classifier correct? In terms of the confusion matrix C, the precision Pi of predicted class value i is given by:
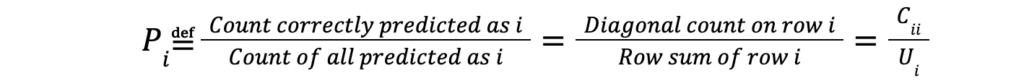
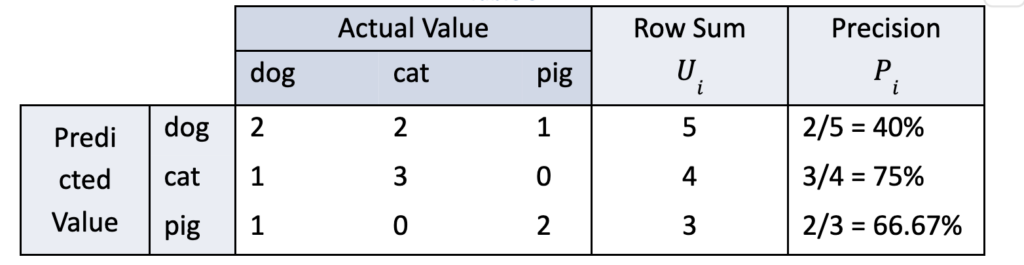
The precision of predicted class values dog, cat, and pig are calculated using the equation above the table. High precision implies that a spam detection classifier makes few false positives, and this is useful because the cost of false positives is high.
When Recall Matters
Recall measures how many actual positives the model captures. While precision is defined on predicted class values, recall is defined on the actual class values. Recall answers the following question: How often does the classifier predict an actual class value correctly? In terms of the confusion matrix C, the recall Rj of actual class value j is given by:
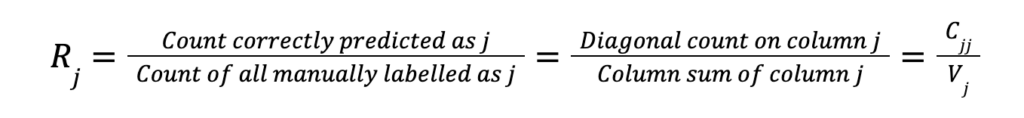
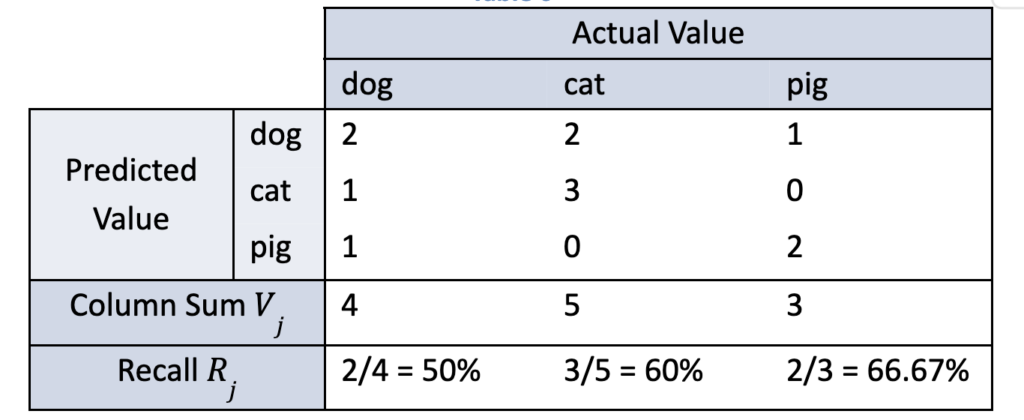
As an example, the recall of the actual class values dog, cat, and pig are calculated using the above equation from the confusion matrix values and column sums computed in this table. Although instructive, one must not lose sight of the importance of such calculations when related to improving outcomes in life dependent industries like healthcare.
A wrong medical diagnosis – e.g., for cancer – could have irreparable consequences. Hence, high recall is vital. Proper cancer diagnosis relies upon data that is a case of rare instance, and with typical synthetic data products, they remove these data outliers and create a dangerous inaccuracy. See Predicting Rare Instances for AI/ML in a GDPR World
Tradeoff and Testing Data
Precision and recall often conflict. Improving one can degrade the other. Consider using normalized precision and recall and prove a lower bound linking the two. This insight helps define acceptable tradeoffs. With PII generated by a data product like tomtA.ai, you can simulate rare but critical edge cases to explore these tradeoffs safely without violating data privacy laws like GDPR.
Takeaway
Precision and recall help evaluate model behavior under risk-sensitive scenarios. Use privacy preserving data generation products like tomtA.ai and avoid synthetic data products to test these tradeoffs before deploying real models. Stay tuned for our next blog in the “Mastering Data Quality for Safe & Scalable AI” series: The Confusion Matrix Demystified – A Simple Tool with Big Insights.
Request our full technical paper at the “Book a Demo” button on our website.