
Fifth in a Series: Mastering data quality for safe and scalable AI
Saibal Banerjee, PhD and Steven Atneosen, JD
Introduction
Every AI practitioner knows the uneasy balance: boosting precision usually costs recall, and maximizing recall often tanks precision. Yet in high-stakes workflows – healthcare diagnostics, fraud detection, border security, or financial approvals – “intuition” about this tradeoff isn’t enough. You need formal, provable bounds to ensure your system operates safely and transparently.
Our CTO’s research paper “Accuracy, Precision, Recall, and all that” (the “Paper”) introduces exactly that: a mathematically rigorous relationship between precision, recall, and accuracy. This new perspective doesn’t just guide threshold-tuning; it helps build trustworthy AI pipelines that meet regulatory and operational requirements.
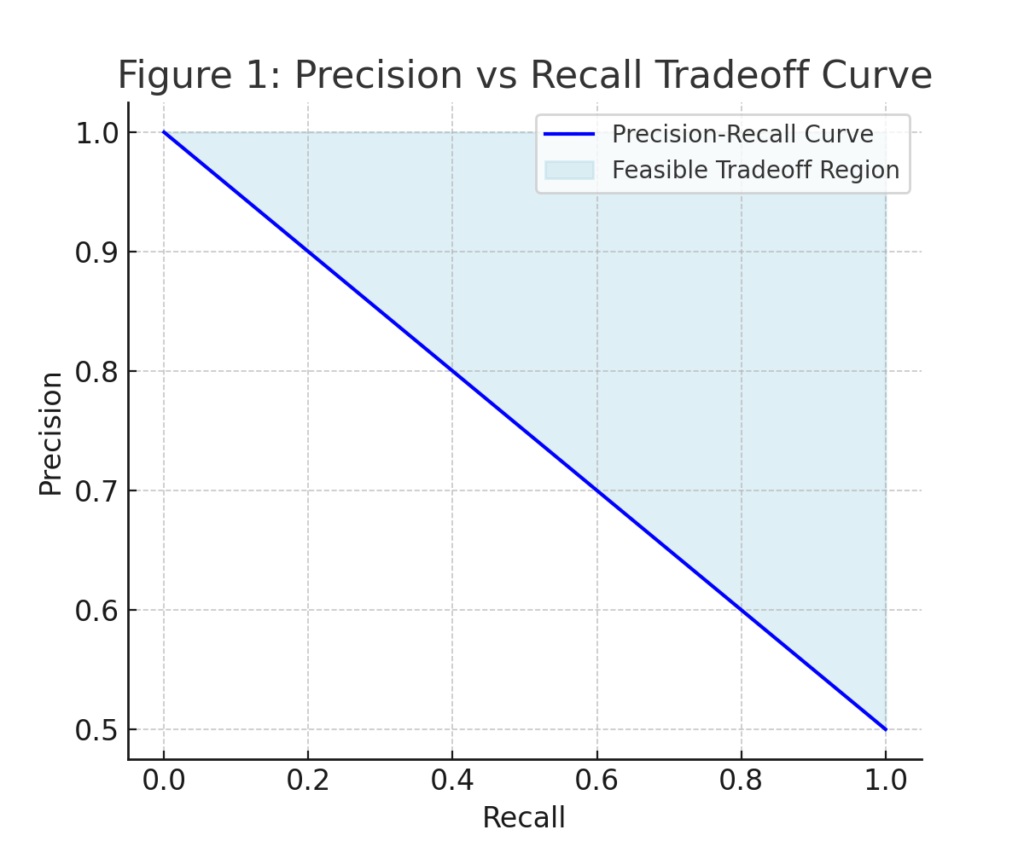
The Precision–Recall Tradeoff
Precision asks: Of all the predictions made as positive, how many are correct?
Recall asks: Of all the actual positives, how many did we correctly capture?
Formally:

High precision reduces false alarms (good for email spam filters). High recall reduces misses (good for cancer screening). But both can’t be maximized simultaneously without limits.
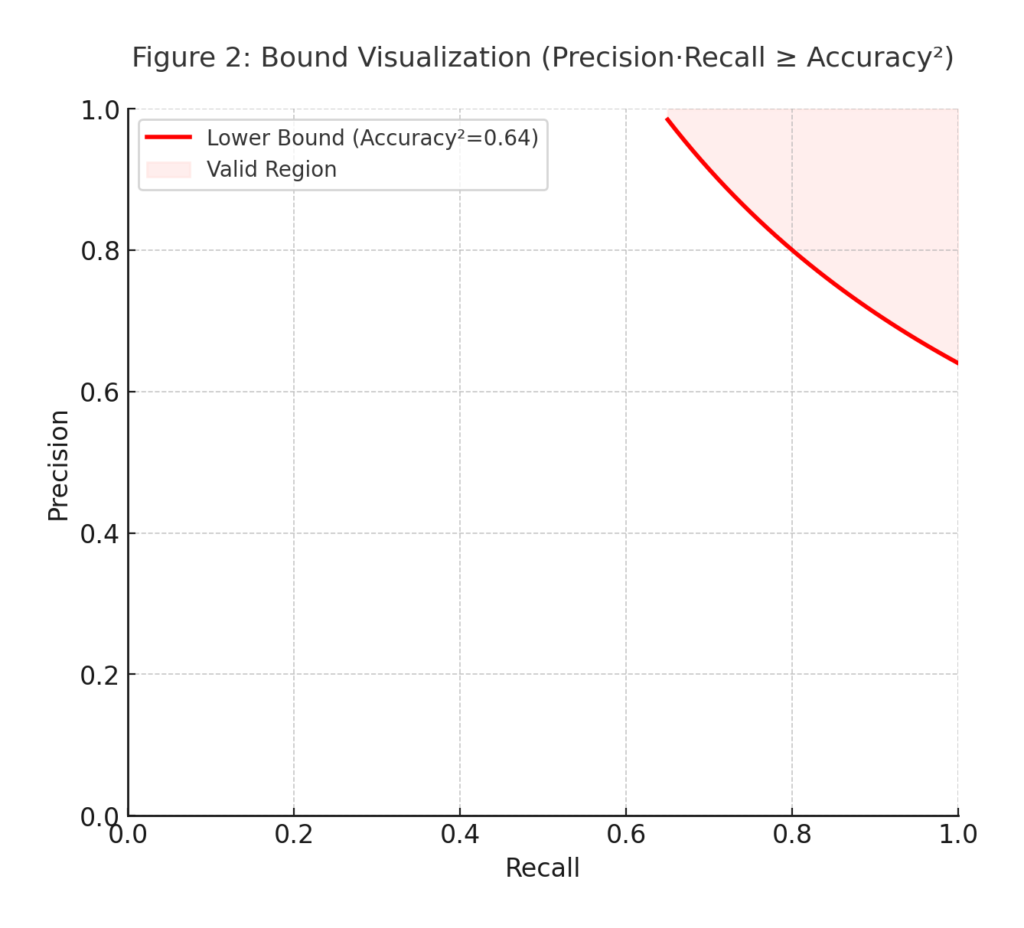
The Formal Bound
The Paper provides the following result:

This bound, derived using the Cauchy–Schwarz inequality, guarantees a minimum feasible region for model performance.
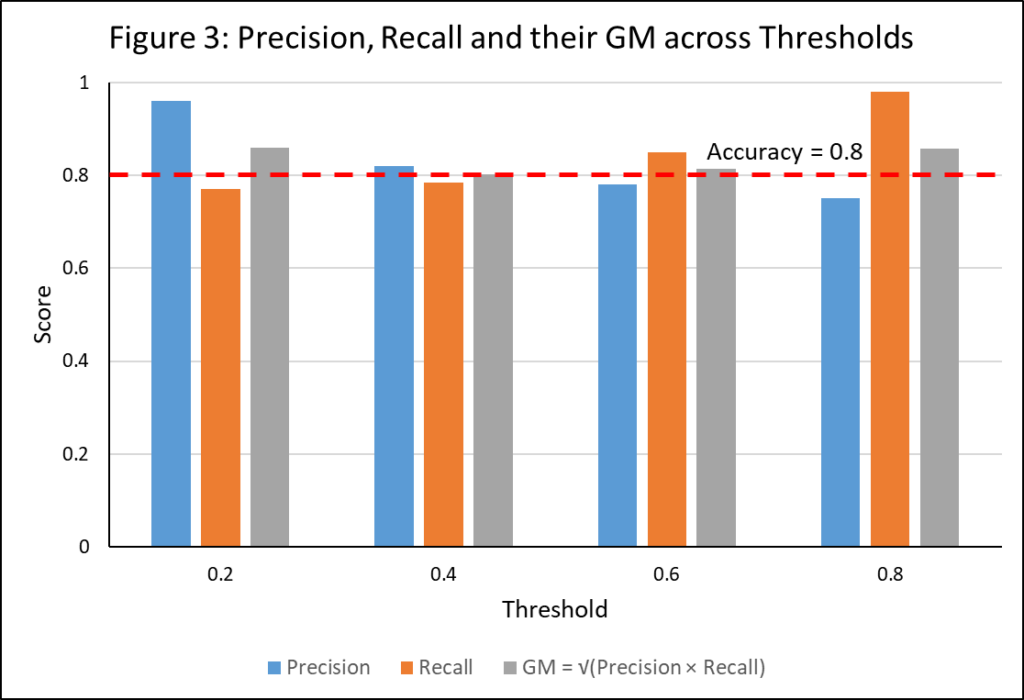
Why This Matters in Practice
This result means your model’s precision and recall aren’t just free-floating metrics; they’re mathematically tethered to accuracy. You can now:
- Set Minimum Floors: Establish provable lower bounds for safety-critical tasks.
- Audit Tradeoff Decisions: Explain to compliance teams why certain recall thresholds (say, in anti-money-laundering models) are mathematically defensible.
- Tune with Confidence: Optimize thresholds with quantifiable guarantees, not guesswork.
Use Case: Phishing Detection in Finance
A financial institution deploys a phishing-email detection model. False negatives (missed phishing attacks) risk customer accounts, while false positives flood IT teams with false alerts.
- By applying the precision-recall bound, the risk team proves that even if they maximize recall, precision cannot drop below a mathematically determined minimum (linked to accuracy).
- Regulators are reassured by the formal guarantee, rather than hand-wavy performance claims.
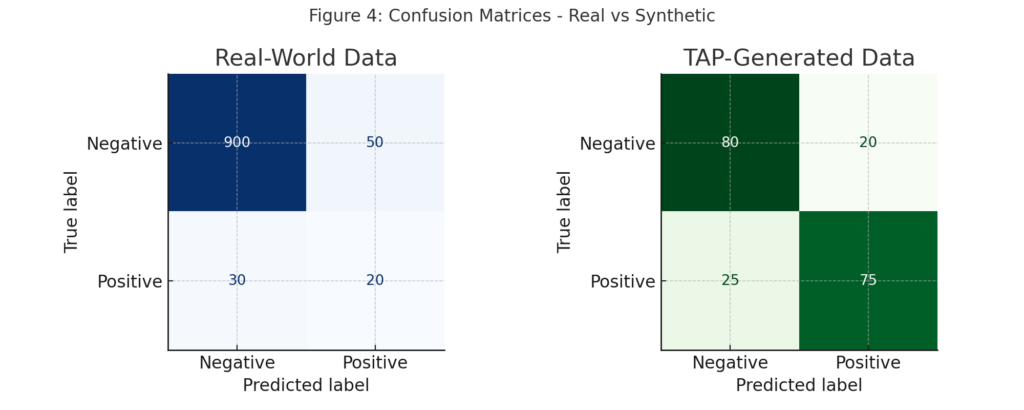
Computational Differential Privacy Derived Data to Explore Boundaries
Here’s where True Atomic Privacy comes in:
- With tomtA.ai’s True Atomic Privacy (TAP) data generation solution (https://tomta.ai/), you can safely simulate rare or sensitive cases – like spear-phishing attacks targeting specific executives – without exposing real PII.
- By generating – let’s call them “synthetic data” test sets for short – that deliberately vary class overlaps or inject controlled ambiguity, teams can stress-test the precision-recall-accuracy relationship across worst-case scenarios.
- This ensures models remain robust before deployment, while preserving privacy.
Use Case: Biometric Security at Borders
Border agencies face false-match risks in facial recognition. A model tuned for high recall (catch all possible matches) risks flagging innocent travelers, while one tuned for high precision risks missing impostors.
With TAP-generated synthetic biometric data – including twins, aged versions of faces, and adversarial modifications – teams can chart precision-recall tradeoffs while still respecting data privacy laws. The mathematical bound ensures their performance guarantees hold even under edge cases.
Conclusion
The proven bound between precision, recall, and accuracy reframes how AI teams approach model evaluation. No longer is it about “finding balance” through intuition – it’s about operating within mathematically safe regions.
With tomtA.ai’s True Atomic Privacy synthetic data, you can:
- Stress-test tradeoffs on sensitive workflows without risking exposure
- Document provable guarantees for regulators and stakeholders
- Build AI systems that are not just powerful, but safe and scalable
Learn more about True Atomic Privacy (https://tomta.ai/) and how it can help you prove, not just assume, the safety of your AI.
Stay tuned for our next blog in the “Mastering Data Quality for Safe & Scalable AI” series: F1 Score and Beyond. When You Need One Metric to Rule Them All
Request our full technical paper at the “Book a Demo” button on our website.