
Sixth in a Series: Mastering data quality for safe and scalable AI
Saibal Banerjee, PhD and Steven Atneosen, JD
Introduction.
AI practitioners face a paradox: the more complex the model, the more elusive its reliability becomes. Precision and recall are essential metrics, but each tells only part of the story. When both false positives and false negatives carry real consequences – like approving fraudulent transactions or missing a cancer diagnosis – you need a balanced metric that reflects both risks.
That metric is the F1 score – a single, harmonically balanced measure of your model’s ability to predict safely and accurately.
Yet the F1 score’s reliability depends on the quality and representativeness of your data. Safe data generation tools like True Atomic Privacy (TAP) from tomtA.ai can transform AI workflows to be quick, safe and secure. TAP generates datasets that are proven to be mathematically equivalent to real PII-based data – preserving distributional truth while ensuring absolute privacy. This lets you safely validate F1, precision, recall, and other performance metrics at scale without ever touching regulated or personal data.
F1: The Metric for Safe and Precise AI
The F1 score balances two competing metrics:

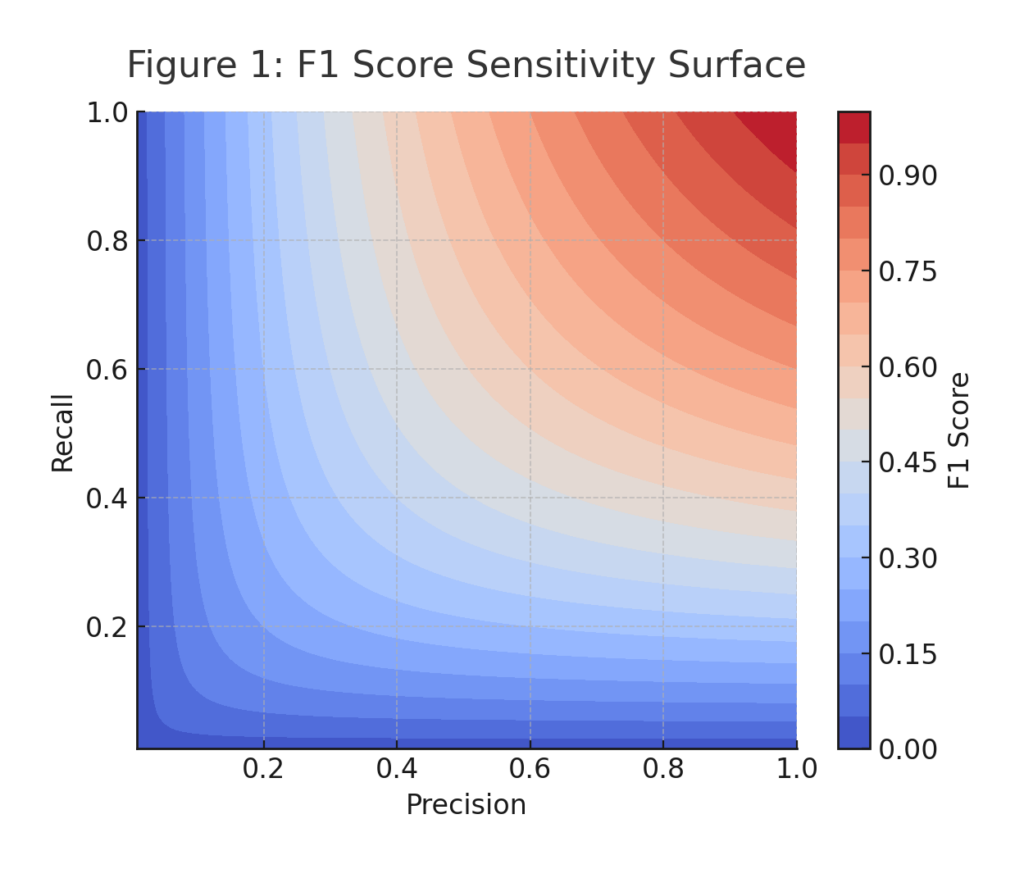
It rewards models that are both accurate and consistent across edge cases. The harmonic mean ensures that if either precision or recall collapses, F1 drops sharply – making it the ideal measure for robustness under uncertainty.
Example:
- Precision = 1.00, Recall = 0.00 → F1 = 0.00
- Precision = 0.90, Recall = 0.90 → F1 = 0.90
- Precision = 0.85, Recall = 0.50 → F1 = 0.63
This sensitivity is a strength – it exposes brittleness before deployment.
Figure 1: F1 Score Sensitivity Surface
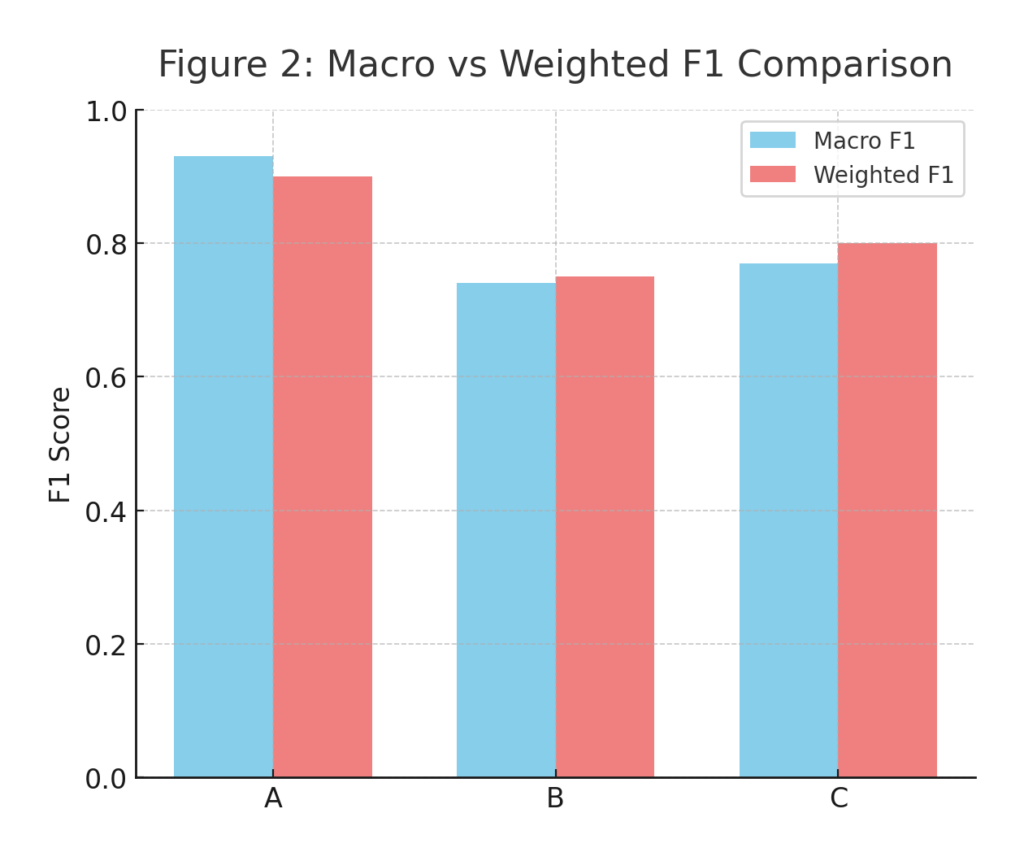
Macro, Micro, and Weighted F1 — Interpreting F1 Across Classes
When working with multi-class or multi-label models, F1 takes several forms, each answering a different operational question:
| Variant | Description | Use Case |
|---|---|---|
| Macro F1 | Unweighted mean of F1 across all classes. Each class matters equally | Fairness auditing, minority group performance |
| Micro F1 | Aggregates all predictions globally before computing F1 | Large-scale deployment health checks |
| Weighted F1 | Weights each class by its prevalence | Real-world operations, imbalanced datasets |
Weighted F1 is typically most representative of production behavior, but macro F1 is vital when ethical or fairness compliance is the focus.

When F1 Alone Isn’t Enough: Introducing Fβ
F1 assumes precision and recall are equally important. Real workflows rarely are.
The Fβ score generalizes F1 to emphasize one over the other:

- β > 1 emphasizes recall (catch every possible positive)
- β < 1 emphasizes precision (avoid false alarms)
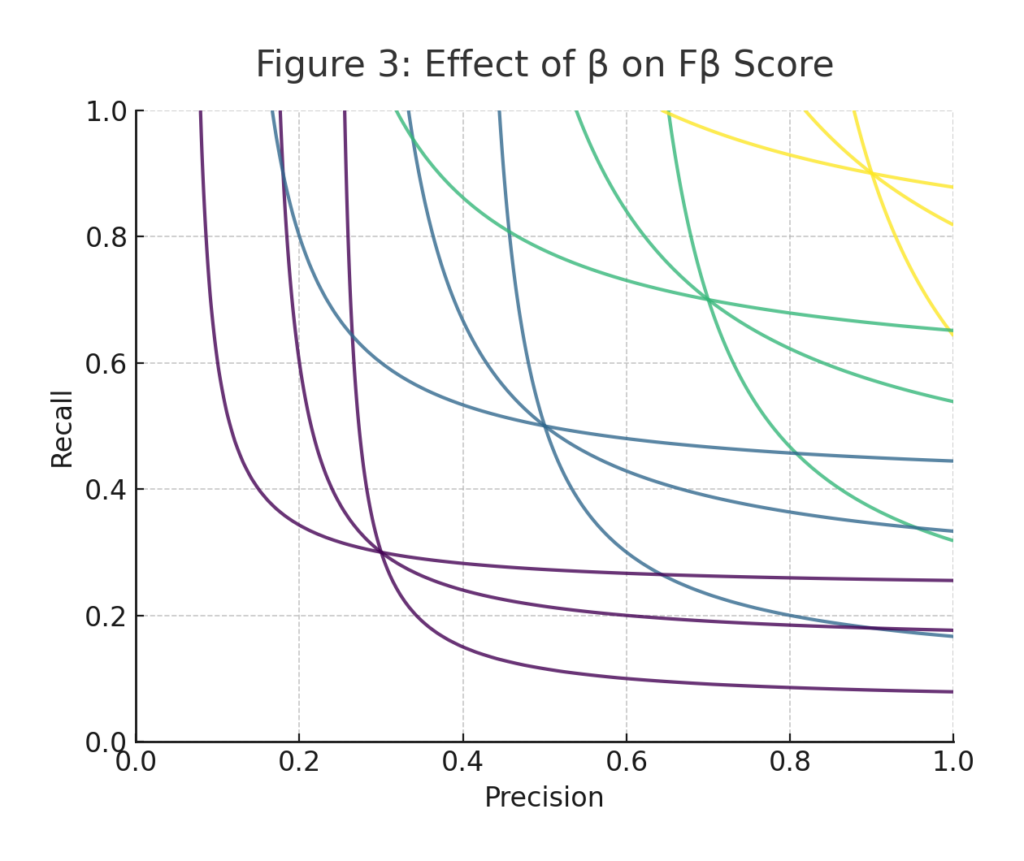
Figure 3 legend: Each color/contour group corresponds to a different β value in the Fβ metric:
- β = 0.5 → prioritizes precision (penalizes false positives less harshly)
- β = 1.0 (F1) → balances precision and recall equally
- β = 2.0 → prioritizes recall, making it suitable for safety-critical detection tasks where missing a positive is very costly
The contour lines show combinations of precision and recall that yield the same Fβ score for each β value. Comparing these shapes reveals how changing β shifts “acceptable” regions of performance.
Testing F1 Robustness Using True Atomic Privacy (TAP)
The biggest risk in relying on F1 is false confidence – measuring it only on real, static, and possibly biased datasets.
TAP changes that. With True Atomic Privacy, you can:
- Generate perfectly balanced synthetic populations to test metric sensitivity.
- Simulate real-world drift (like seasonal or demographic shifts) safely.
- Inject structured noise to evaluate resilience to ambiguity.
- Validate fairness without risking exposure of real identities.
All while maintaining mathematical fidelity to the underlying data distribution.
Example: Healthcare Diagnostics
A hospital trains an imaging model to detect early-stage tumors. Using real data is risky under HIPAA, so they use TAP to generate privacy-preserving patient-level synthetic scans.
They then run thousands of tests on different tumor-size distributions and verify that the F1 score remains above the regulatory threshold.
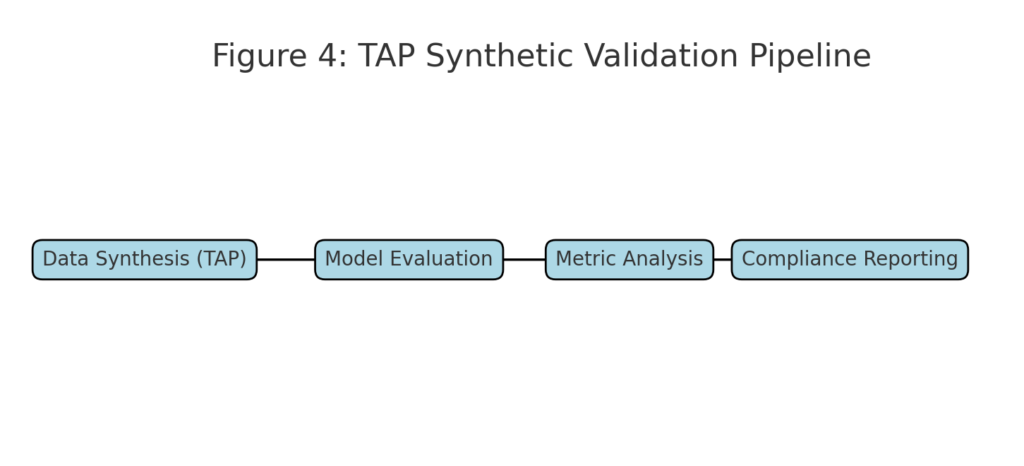
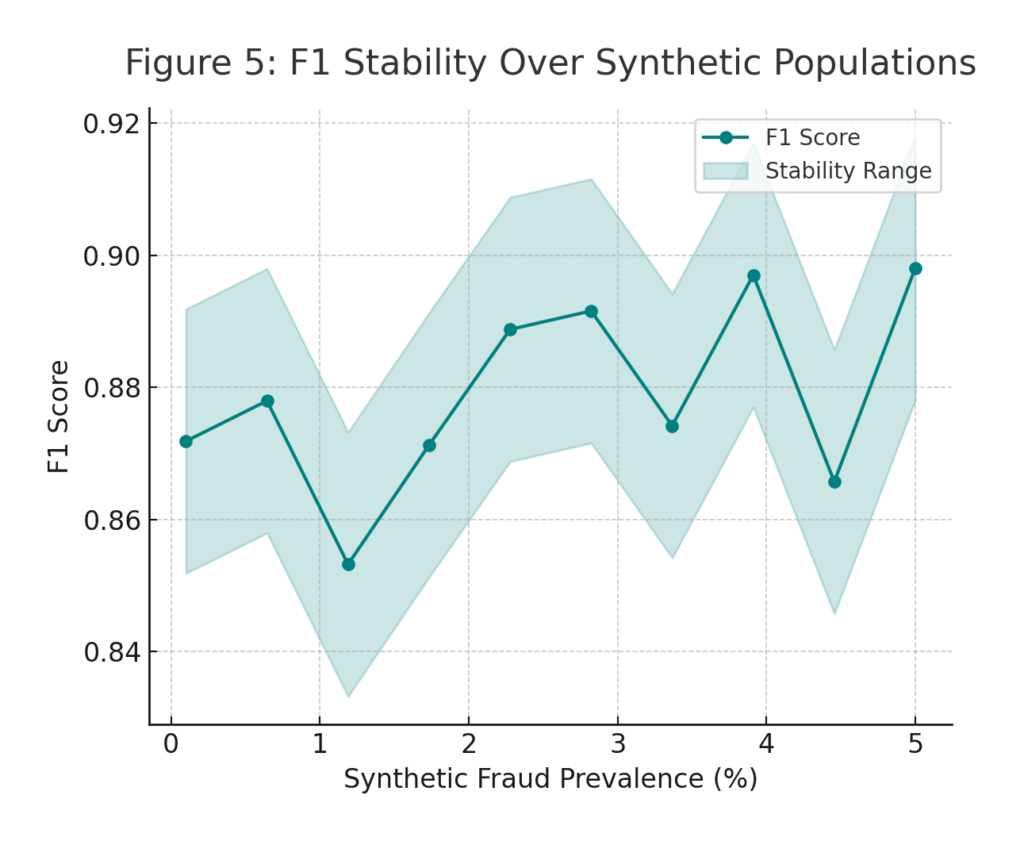
Use Case: Fraud Detection Under Dynamic Risk
An e-commerce platform detects fraudulent accounts using a model trained on billions of transactions. In production, fraud patterns evolve rapidly. By leveraging TAP:
- Teams simulate synthetic transaction streams reflecting new fraud strategies.
- F1 stability is continuously monitored across populations.
- Alerts trigger when the F1 score goes out of bounds of an adaptive threshold, indicating data or concept drift.
The result: a self-auditing, privacy-safe AI system that remains both accurate and compliant.
Conclusion
The F1 score is more than a performance metric – it’s a lens through which we evaluate the trustworthiness of AI systems. But to use it safely, you must control what data you evaluate it on.
True Atomic Privacy transforms how AI teams validate models:
- Safety-first: eliminates PII exposure risks
- Precision-tested: preserves real-world statistical behavior
- Scalable: supports iterative validation at enterprise scale
When precision and recall define the edges of AI reliability, F1 measures the balance, and TAP ensures that balance is grounded in safety, privacy, and truth.
👉 Learn how True Atomic Privacy ensures your AI workflows are both safe and precise.
One response to “F1 Score and Beyond — When You Need One Metric to Rule Them All”
Understanding the balance between precision and recall is definitely key for reliable AI, and it’s interesting to consider how F1 score attempts to address that.